Hadoop workstation-only Trunk update
Introduction
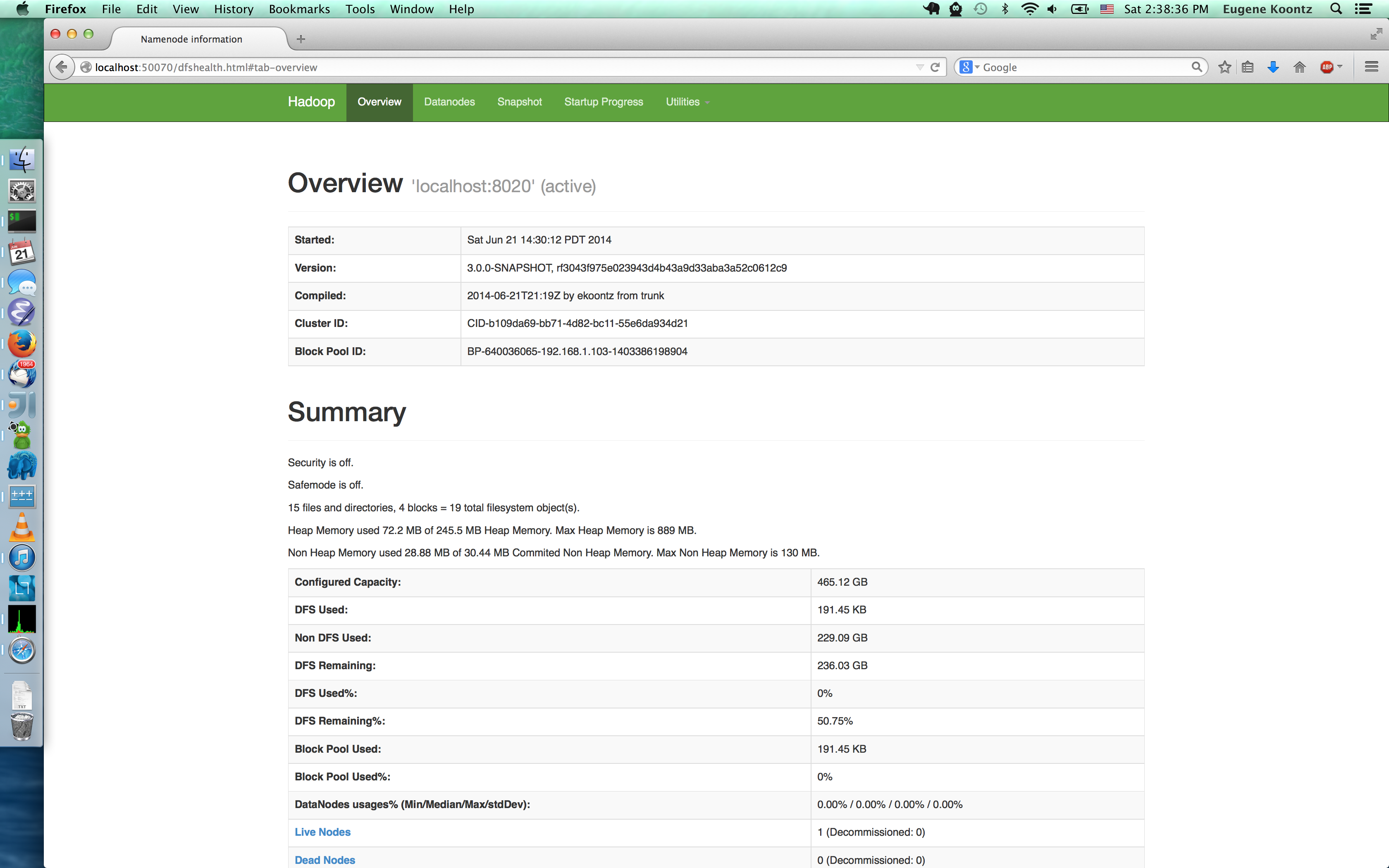
I decided to revist Hadoop trunk today to see how easy it is to get everything (HDFS + MapReduce) working. The good news is, it’s gotten really easy!
Reservations
I see this is having three main audiences: - application developers needing a Hadoop to build and test against - Hadoop internal developers who want to work on features and bugs
As such, I’ve left out a few things that would be needed for larger-scale deployments:
- I’ve only tested this on MacOS X. At some point I’ll try Linux.
- I’ve not tried native code-building yet.
- Haven’t messed with getting Kerberos working.
- No High-Availability.
Build
git clone https://github.com/apache/hadoop-common.git
cd hadoop-common
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.7.0_51.jdk/Contents/Home
export PATH=$JAVA_HOME/bin:$PATH
java -version
The last command returns (for me):
java version "1.7.0_51"
Java(TM) SE Runtime Environment (build 1.7.0_51-b13)
Java HotSpot(TM) 64-Bit Server VM (build 24.51-b03, mixed mode)
These last two odd-looking commands are from BUILDING.txt:
sudo mkdir $JAVA_HOME/Classes
sudo ln -s /Library/Java/JavaVirtualMachines/jdk1.7.0_51.jdk/Contents/Home/lib/tools.jar /Library/Java/JavaVirtualMachines/jdk1.7.0_51.jdk/Contents/Home/Classes/classes.jar
mvn package -Pdist -DskipTests -Dtar
The -Dtar is probably not needed for what we are doing here, but
would be useful if you want to reproduce on several hosts for testing at-scale.
Configuration
Each of the below files are in
hadoop-dist/target/hadoop-3.0.0-SNAPSHOT/etc/hadoop. Edit each
so they look like the below.
core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:8020</value>
</property>
</configuration>
mapreduce-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
hdfs-site.xml
Can be left as-is (i.e. empty).
Start HDFS and MapReduce
Startup script
In hadoop-dist/target/hadoop-3.0.0-SNAPSHOT/bin, create a file
start.sh that looks like:
#!/bin/sh
ps -ef | grep java | egrep Node\|Manager\|HistoryServer | awk '{print $2}' | xargs kill
bin/hdfs namenode &
bin/hdfs datanode &
bin/yarn timelineserver &
bin/yarn resourcemanager &
bin/yarn nodemanager &
Format NN
cd hadoop-dist/target/hadoop-3.0.0-SNAPSHOT
bin/hdfs namenode -format
Start all daemons!
sh bin/start.sh
Test HDFS
bin/hadoop fs -copyFromLocal ../../../BUILDING.TXT hdfs://localhost:8020/
bin/hadoop fs -ls /
Test MapReduce
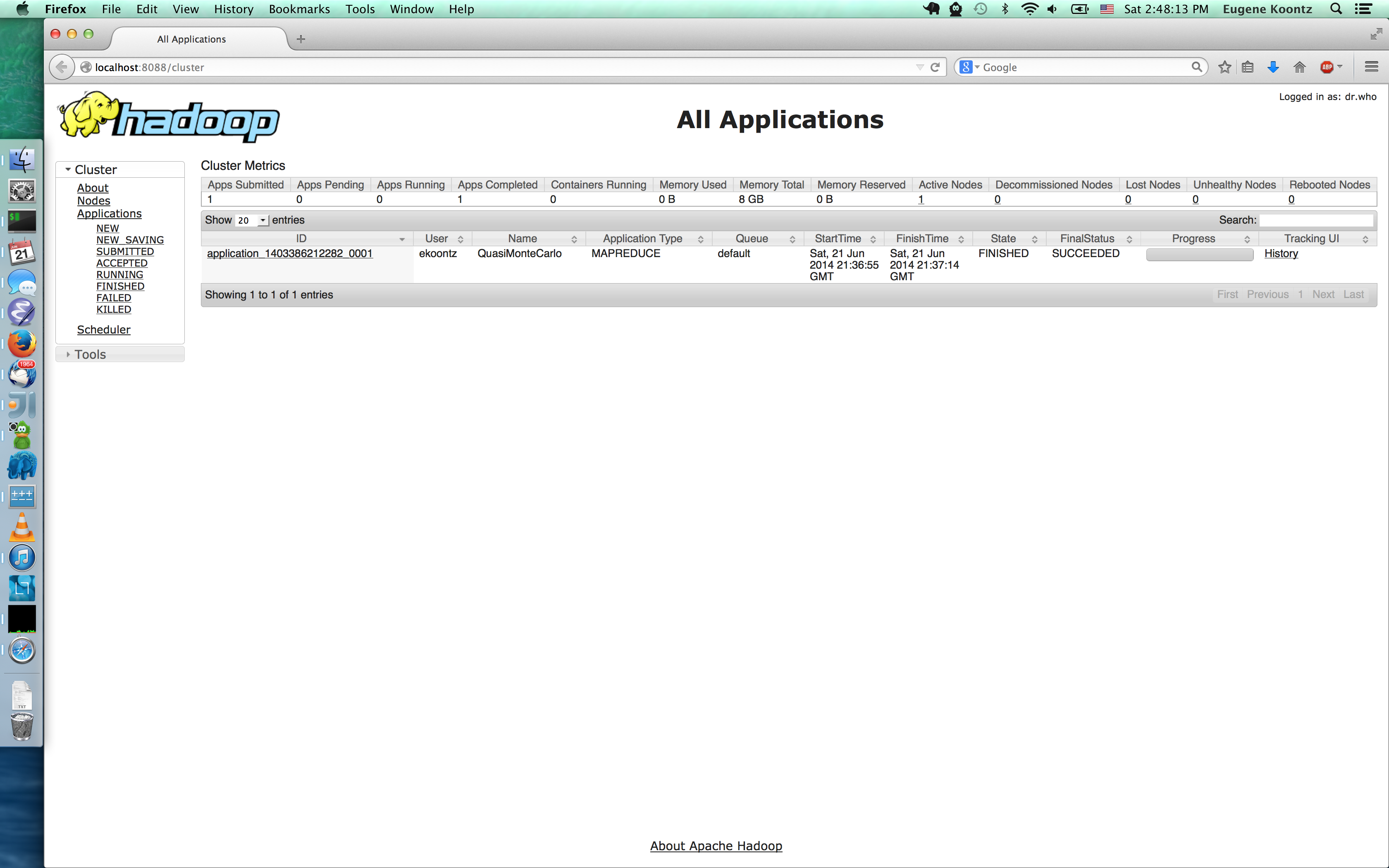
bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0-SNAPSHOT.jar pi 10 10
Web UIs
blog comments powered by Disqus